Chapter 1. 데이터 표현 디자인 패턴
1. 간단한 데이터 표현
1 - 1. 수치 입력
스케일링이 필요한 이유
- 머신러닝 모델(랜던 포레스트, 서포트 벡터 머신, 신경망)은 수치 기반으로 작동하므로 입력값이 수치로 되어 있다면 변경하지 않고 모델에 적용 가능
- 스케일링이 필요한 이유
- 경사 하강법 옵티마이저는 손실 함수의 곡률이 증가함에 따라 수렴하는 데 더 많은 단계 필요
- 특징의 상대적인 크기가 더 크다면 미분도 큰 경향이 있어, 손실 함수의 곡률이 크면 비정상적인 가중치 업데이트로 이어지기 때문
- 비정상적으로 큰 가중치 업데이트는 수렴하는 데 더 많은 단계가 필요하므로 계산의 부하가 증가
- 데이터를 [-1, 1] 범위에서 '중앙에 배치'하면 오류 함수가 더 완만
- 스케일링된 데이터로 학습시킨 모델은 더 빨리 수렴하는 경향, 학습 속도가 더 빨라지거나 비용이 저렴
- 또한 [-1, 1] 범위에서 가장 높은 부동 소수점 정밀도를 얻음
- 경사 하강법 옵티마이저는 손실 함수의 곡률이 증가함에 따라 수렴하는 데 더 많은 단계 필요
from sklearn import datasets, linear_model
import timeit
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y = True)
raw = diabetes_X[:, None, 2]
max_raw = max(raw)
min_raw = min(raw)
scaled = (2*raw - max_raw - min_raw)/(max_raw - min_raw)
def train_raw():
linear_model.LinearRegression().fit(raw, diabetes_X)
def train_scaled():
linear_model.LinearRegression().fit(scaled, diabetes_y)
raw_time = timeit.timeit(train_raw, number = 1000)
scaled_time = timeit.timeit(train_scaled, number = 1000)
print("모델 적용 시간 :", raw_time)
print("스케일 적용 모델 적용 시간 :", scaled_time)
print("시간 차 :", (raw_time - scaled_time))
선형 스케일링
- 최소-최대 스케일링
- 최댓값과 최솟값을 학습 값 내에서 추정 ㅡ> 아웃라이너 값일 가능성이 높음
- 아웃라이너를 최댓값 또는 최솟값으로 설정시 실제 데이터가 [-1, 1] 범위 내에서 매우 좁은 범위로 축소
x1_scaled = (2*x1 - max_x1 - min_x1) / (max_x1 - min_x1)
- 클리핑(최대-최소 스케일링과 함께 사용)
- 최댓값, 최솟값 추정보다는 '합리적인' 값을 사용하면 아웃라이어 문제 해결 가능
- 선형 스케일링시 [-1, 1] 범위에 들어오게 되는데, 이 방법은 아웃라이어값을 -1 or 1로 처리
- Z점수 정규화
- 추정한 평균과 표준편차를 사용하여 선형적으로 스케일링
- 학습 데이터가 표준편차로 정규화되어 스케일링한 값의 평균은 0이 되고 분산은 1
- 대부분은 [-1, 1] 사이에 있지만, 범위를 벗어나는 값은 여전히 존재
- 데이터가 정규분포를 따를 경우 유용
x1_scaled = (x1 - mean_x1) / stddev_x1
- 윈저라이징
- 학습 데이터셋의 경험적 분포를 사용하여 데이터값의 10번째 및 90번째 백분위수(또는 5번째, 95번째)에 해당하는 경계로 데이터셋을 클리핑
- 이후에 최대-최소 스케일링을 적용
비선형 변환
- 데이터가 편향되어 있거나 종형 곡선처럼 분포되어 있지 않다면, 비선형 변환을 하는 것이 좋음
- 일반적으로 스케일링전에 입력값의 로그화(시그모이드 함수, 다항식 전개도 있음)
- 치우친 분포를 처리하는 또 다른 방법은 박스-콕스 변환과 같은 모수 변환 기술을 사용
- 박스-콕스 변환은 하나의 파라미터, 람다를 사용하여 분산이 더 이상 크기에 의존하지 않도록 '이분산성' 제어
GitHub - yunho0130/ml-design-patterns: O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드
O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드 저장소 - GitHub - yunho0130/ml-design-patterns: O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드 저장소
github.com
수의 배열
- 입력 배열은 전체적인 통계를 활용(평균, 중앙값, 최솟값, 최댓값)
- 경험적 분포(10분위, 20분위, 백분위수 등)
- 입력 배열을 마지막 3개 쪼는 다른 고정된 수의 항목으로 표현
1 - 2. 카테고리 입력
- 더미 코딩과 원ㅡ핫 인코딩이 존재
- 하지만 최신 머신러닝 알고리즘은 선형적으로 독립적일 필요가 없어 원-핫 인코딩을 주로 사용
- 원ㅡ핫 인코딩 주의할점
- 요일 데이터를 숫자로 처리할 경우, 연속적인 값이 아닌 인덱스에 불과
- 요일을 카테고리 특징으로 취급하는 것이 더 나은 이유는, 금요일의 교통량이 목요일과 토요일의 교통량으로부터 영향을 받지 않음
- 대부분 도시에서 교통량은 주말인지 주중인지에 따라 다르고, 일부 이슬람 국가는 목요일, 금요일이 주말인 경우가 있음
- 다른 예로 쌍둥이, 세쌍둥이 데이터 경우 카테고리 구분에 대한 예시가 충분히 있어야 하는 경우도 있음
2. 디자인 패턴 1 : 특징 해시
- 디자인 패턴은 카테고리 특징과 관련해 발생 가능한 세 가지 문제인 불완전한 어휘, 카디널리티로 인한 모델 크기, 콜드 스타트를 해결
3. 디자인 패턴 2 : 임베딩
- 임베딩은 학습 문제와 관련된 정보가 보존되는 방식으로 높은 카디널리티 데이터를 저차원 공간에 매핑하는, 학습 가능한 데이터 표현
- 임딩 디자인 패턴은 학습 가능한 가중치가 있는 임베딩 계층을 통해 입력 데이터를 전달하여 낮은 차원에서 큰 카디널리티를 가진 데이터를 밀집시켜 표현하는 문제 해결
GitHub - yunho0130/ml-design-patterns: O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드
O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드 저장소 - GitHub - yunho0130/ml-design-patterns: O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드 저장소
github.com
3 - 1. 솔루션
텍스트 임베딩
- 임베딩 계층을 사용하기에 유리
- 케라스에서 임베딩을 사용시 각 단어에 대한 토큰화 + 토큰화를 사용해 임베딩 계층에 매핑
- 토큰화는 어휘의 각 단어를 색인에 매핑하는 조회 테이블
- 토큰화된 인덱스는 원ㅡ핫 인코딩에서 값이 1인 위치에 해당하는 각 단어의 원-핫인코딩
from tensorflow.keras.preprocessing.test import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_tests(titles_df.title)
- texts_to_sequences 메서를 사용하며 매핑
integerized_titles = tokenizer.texts_to_sequences(titles_df.title)
- 토큰화에는 나중에 임베딩 계층을 만드는 데 사용할 기타 정보 포함
- VOCAB_SIZE = 인덱스 조회 테이블의 원소 수
- MAX_LEN = 데이터셋에 있는텍스트 문자열의 최대 길이
VOCAB_SIZE = len(tokenizer.index_word)
MAX_LEN = max(len(sequence) for sequence in integerized_titles
- 모델을 만들기 전 데이터셋 제목 전처리
- 제목을 문장 최대 길이로 패딩하는 라이브러리 pad_sequence 존재
- create_sequences 함수는 제목과 최대 문장 길이를 입려긍로 취하고, 문장 최대 길이에 패딩된 토큰에 해당하는 정수 목록 반환
from tensorflow.keras.preprocessing.sequence import pad_sequences
def create_sequences(texts, max_len = MAX_LEN):
sequences = tokenizer.texts_to_sequences(texts)
padded_sequences = pad_sequences(sequences, max_len, padding = 'post')
return padded_sequences
- 단순한 임베딩 계층을 구현하여 단어 정수를 고밀도 벡터로 변환하는 심층 신경망
- 케라스의 Embedding 계층은 특정 단어의 정수 인덱스에서 고밀도 벡터로의 매핑
- 임베딩의 차원은 output_dim의해 결정
- input_dim 인수는 어휘의 크기
- input_shape는 입력 시퀀스의 길
model = models.Sequential([layers.Embedding(input_dim = VOCAB_SIZE + 1,output_dim = embed_dim,
input_shape = [MAX_LEN]),
layers.Lambda(lambda x: tf.reduce_mean(x, axis = 1)),
layers.Dense(N_CLASSES, activation = 'softmax')])- 임베딩 계층이 반환하는 단어 벡터의 평균을 내리면, 임베딩 계층과 완전 연결 소프트맥스 계층 사이에 커스텀 케라스 lambda 계층을 넣어야함 ㅡ> 완전 연결 소프트맥스 계층에 공급할 평균
이미지 임베딩
- 텍스트는 매우 저밀도의 입력을 처리하지만, 이미지나 오디오는 일반적으로 원시 픽셀 또는 주파수 정보를 포함하는 여러 채널을 가진 고밀도의 고차원 벡터로 구성
- 이런 데이터에 대한 임베딩은 낮은 차원 공간에서 입력과 관련된 표현을 형성
- Inception, ResNet과 같은 복잡한 CNN은 수백만 개의 이미지와 수천 개의 분류 라벨이 포함된 ImageNet과같은 대형 이미지 데이터셋에서 학습
- 그런 다음 마지막 소프트맥스 계층 모델에서 제거
- 이미지/캡션 쌍의 방대한 데이터셋에서 모델 아키텍처를 학습함으로써 인코더는 이미지에 대한 효율적인 벡터 표현을 학습
- 디코더는 이 벡터를 텍스트 켑션으로 변환하는 방법을 학습. 인코더는 Image2Vec 임베딩 머신

3 - 2. 작동 원리
- 임베딩 계층은 신경망의 또 다른 숨겨진 계층
- 가중치는 카디널리티가 큰 차원 각각에 연결되고, 나머지 네트워크를 통해 출력
- 따라서 임베딩을 생성하는 가중치는 신경망의 다른 가중치와 마찬가지로 경사 하강법 프로세스를 통해 학습
- 벡터 임베딩은 학습 데이터 입력 특징값의 가장 효율적인 저차원 표현을 나타냄
3 - 3. 트레이드오프와 대안
- 임베딩 사용의 단점은 데이터 표현이 손상
- 카디널리티가 큰 표현을 저차원 표현으로 이동시키는 과정에서 정보 손실이 발생하지만, 그 대가로 항목 간의 밀착도와 콘텍스트에 대한 정보를 얻음
임베딩 차원의 선택
- 표현의 손실 여부는 임베딩 계층의 크기에 따라 다름
- 임베딩 계층의 출력 차원이 작을 경우, 많은 정보가 작은 벡터 공간에 강제로 들어가 콘텍스트 정보가 훼손
- 반대로 너무 크다면 임베딩의 특징 각각의 중요성을 잃음
- 원ㅡ핫 인코딩은 임베딩 차원의 극단적인 예시
- 경험으로 부터 나온 규칙
- 고유한 카테고리형 원소 총수의 네제곱근 사용
- 임베딩 차원이 고유한 카테고리형 원소 총수 제곱근의 약 1.6배
Introducing TensorFlow Feature Columns
News and insights on Google platforms, tools, and events.
developers.googleblog.com
GitHub - fastai/fastai2: Temporary home for fastai v2 while it's being developed
Temporary home for fastai v2 while it's being developed - GitHub - fastai/fastai2: Temporary home for fastai v2 while it's being developed
github.com
오토인코더
- 라벨이 지정된 대규모 데이터셋을 우회하는 방법
- 기본적으로 임베딩 계층은 병목 계층. 인코더는 고차원을 저차원으로, 디코더는 저차원을 고차원으로 매핑
- 모델은 일반적으로 재구성 오류의 일부 변형에 대해 학습되어 모델의 출력이 입력과 최대한 유사해지게 만듦

- 입력과 출력이 비슷하여 추가 라벨이 필요하지 않음
- 인코더는 최적의 비선형 차원 감소를 학습
- PCA가 선형으로 차원 감소를 수행하는 방법과 유사하게, 오토인코더의 병목계층은 임베딩을 통해 비선형 차원으로 감소
- 오토인코더를 통해 모델의 성능을 올릴 수 있음
- 오토인코더를 보조 학습 작업으로 사용하여 라벨이 지정되지 않은 데이터의 카디널리티를 감소
- 보조 오토인코더가 생성한 임베딩을 사용하여 일반적으로 라벨이 훨씬 적은 실제 이미지 데이터의 분류 문제를 해결
- 모델은 낮은 차원에 대한 가중치만 학습하면 되므로 모델의 성능을 높일 수 있음
- 구조화된 데이터에 딥러닝 기술을 적용한 연구 사례
Introducing TensorFlow Feature Columns
News and insights on Google platforms, tools, and events.
developers.googleblog.com
콘텍스트 언어 모델
- Word2Vec과 같은 콘텍스트 언어 모델, BERT와 같은 마스킹 언어 모델은 라벨이 부족하지 않도록 학습 작업을 문제로 변경
- Word2vec은 얕은 신경망을 사용하고 CBOW와 skip-gram 모델을 결합하여 임베을 구성하는 방식
- 두 모델의 공통된 목표는 중간 임베딩 계층을 사용하여 입력 단어를 대상 단어에 매핑하고 단어의 콘텍스트를 학습하는 것이지만, 보조적인 목표로 단어의 콘텍스트를 가장 잘 포착하는 저차원 임베딩을 학습하는 효과도 있음
- BERT는 마스킹된 언어 모델과 다음 문장 예측을 사용하여 학습
- 어떤 종류의 텍스트 코퍼스는 라벨이 지정된 데이터셋으로 적합
- BERT는 영문 위키피디아와 북스코퍼스로 학습했지만, 보조 작업으로 학습했음에도 불구하고 BERT 또는 Word2vec에서 학습된 임베딩은 다른 다운스트림 학습 작업에 사용될 매우 강력한 효과를 가짐
- Word2vec, NNLM, GLoVE, BERT를 머신러닝 모델에 추가하면 텍스트 특징을 처리할 수 있음
데이터 웨어하우스에서의 임베딩
- 구조화된 데이터에 대한 머신러닝은 데잍 웨어하우스의 SQL에서 직접 수행하는 것이 best
- 많은 문제는 구조화된 데이터와 자연어 텍스트, 또는 이미지 데이터를 혼합해야함
- 자연어는 열로, 이미지는 파일에 대한 URL로 저장
- 이럴 경우에는 텍스트 열 또는 이미지의 임베딩을 배열 형식의 열로 추가로 저장해두면 나중에 머신러닝 문제를 단순화할 수 있음
- 텍스트 임베딩을 만들기 위해 텐서플로 허브에서 빅쿼리로 스위블과 같은 사전 학습된 모델을 로드
create or replace model advdata.swivel_text_embed
options(model_tyep = 'tensorflow', model_path = 'gs://BUCKET/swival/*')
- 그런 다음 모델을 사용하여 자연어 텍스트 열을 임베딩 배열로 변환하고 임베딩 조회 테이블를 새 테이블로 저장
create or replace table advdata.comments_embedding as
select
output_0 as comments_embedding,
comments
from ML.predict(model advdata.swivel_test_embed, (
select comments, lower(comments) as sentences
from 'bigquery-public-data.noaa_preliminary_severe_storms.wind_reports'
))
4. 디자인 패턴 3: 특징 교차
- 특징 교차 디자인 패턴은 입력값의 각 조합을 별도의 특징으로 명시적으로 만들어, 모델이 입력 간의 관계를 더 빨리 학습하도록 도움
- 데이터셋에서 +, - 라벨을 구분하는 이진 분류기를 생성
- 값을 구분할 수 있는 좌표가 필요
- 머신러닝을 지원하는 새로운 특징을 생성해야하므로, 특징 교차를 생성
- 특징 교차란 둘 이상의 카테고리 특징을 연결하여 이들 간의 상호작용을 반영하도록 합성된 특징
- 두 특징을 결합하면 비선형성을 모델 안에 인코딩할 수 있으며, 이를 통해 각 특징이 개별적으로 제공할 수 있었던 것 이상의 예측 능력을 가지게 됨
- 특징 교차를 활용하면 ML 모델이 특징 간의 관계를 더 빠르게 학습 가능
GitHub - yunho0130/ml-design-patterns: O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드
O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드 저장소 - GitHub - yunho0130/ml-design-patterns: O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드 저장소
github.com
4 - 1. 트레이드오프와 대안
- 약간의 전처리를 통해서도 수치 특징에 특징 교차를 적용할 수 있음
- 특징 교차는 모델의 특징의 밀도를 낮추기 때문에 낮은 밀도를 해소하는 기술과 함께 사용 가능
수치 특징 다루기
- 하나의 입력이 m개의 값을 가질 수 있고 다른 입력이 n개의 값을 가질 수 있다면 두 가지의 특징 교차는 m X n개의 원소를 가짐
- 그런데 수치 입력은 밀도가 높고 연속된 값을 사용. 연속 입력 데이터의 특징 교차를 생성하고 가능한 모든 값을 열거하는 것은 불가능
- 대신 연속적인 데이터에 특징 교차를 바로 적용하지 않고 그 전에 데이터를 버킷화하여 카테고리화 가능
- 예를 들어 위도와 경도는 연속적인 입력이며 위도와 경도의 순서 쌍에 의해 위치가 결정되기 때문에 두 입력을 사용하여 특징 교차를 만드는 것이 상식
- 위도와 경도를 그대로 사용하여 특징 교차를 만드는 대신, 각각의 연속적인 값을 비닝해서 binned_latitude, binned_longitude를 만든후 이를 가지고 측징 교차를 생성
import tensorflow.feature_column as fc
# 위도에 대한 버킷 특징 열 만들기
latitude_as_numeric = fc.numeric_column('latitude')
lat_bucketized = fc.bucketized_column(latitude_as_numeric, lat_boundaries)
# 경도에 대한 버킷 특징 열 만들기
longitude_as_numeric = fc.numeric_column('longitude')
lan_bucketized = fc.bucketized_column(longitude_as_numeric, lan_boundaries)
# 위도와 경도의 특징 교차 만들기
lat_x_lon = fc.crossed_column([lat_backetized, lon_bucketized],hash_bucket_size = nbuckets**4)
crosed_feature = fc.indicator_column(lat_x_lon)
큰 카디널리티 다루기
- 특징 교차를 수행하면 카테고리의 카디널리티가 입력 특징의 카디널리티에 비해 몇 배로 증가하기 때문에 특징 교차는 모델 입력의 밀도를 낮춤
- 문제를 해결하려면 특징 교차 결과를 임베딩 계층으로 보내서 저차원 표현을 만드는 방법이 효과적
- 임베딩 디자인 패턴을 사용하면 밀착도를 모델링할 수 있으므로, 특징 교차를 임베딩 계층에 전달하면 모델이 시간/요일 쌍이 모델의 출력에 미치는 영향을 일반화할 수 있음
# 앞에서 위도 / 경도 예시로 사용했던 indicator_column 대신 embedding_column 사용
crossed_feature = fc.embedding_column(lat_x_lon, dimension = 2)
정규화의 필요성
- 카디널리티가 큰 두 카테고리형 특징을 교차시키면 그 커디널리티는 원래 두 특징의 수의 곱이 됨
- 반대로 개별 버킷 항목이 너무 적으면 모델의 일반화 특징이 저하
- 위도와 경도를 예를 들어 매우 미세한 버킷을 사용한다면 모델이 지도의 모든 지점을 기억할 수 있지만, 큰 버킷을 사용하다면 몇 개의 지점만 기억할 수 있고, 자연스럽게 과대적합으로 이어질 수 있음
- 주의할 점은 특징 교차를 위해 결합할 특징을 선택시 상관관계가 높은 두 특징 을 교차하는 것은 권하지 않음
- 두 특징의 상관관계가 높으면 특징 교차의 결과물이 모델에 새로운 정보를 가져오지 않음
5. 디자인 패턴 4: 멀티모달 입력
- 멀티모달 입력 디자인 패턴은 사용가능한 모든 데이터 표현을 연결하여, 복잡한 방식으로 표현할 수 있는 데이터 또는 다양한 유형의 데이터를 표현하는 문제를 해결
GitHub - yunho0130/ml-design-patterns: O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드
O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드 저장소 - GitHub - yunho0130/ml-design-patterns: O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드 저장소
github.com
트레이드오프와 대안
- 멀티모달 입력 디자인 패턴은 동일한 모델에서 서로 다은 입력 형식을 표현하는 방법을 찾아냄
- 서로 다른 유형의 데이터를 혼합하는 것 외에도, 모델이 패턴을 더 쉽게 식별할 수 있도록 동일한 데이터를 다른 방식으로 표현 가능
- 예를 들어 별 1 ~ 5개까지의 평점 필드가 있다면, 이 필드는 수치, 카테고리로도 표현이 가능
- 멀티모달 입력은 두 가지를 의미
- 이미지와 복잡한 메타데이터와 같이 서로 다른 유형의 데이터 결합
- 복잡한 데이터를 여러 방법으로 표현
텍스트의 멀티모달 표현
- 텍스트 데이터의 복잡한 특징을 감안하면, 그로부터 의미를 추출하는 방법은 여러 가지가 있음
- 텍스트에서 테이블 형식의 특징을 추출하는 방법과 함께 텍스트를 표현하는 BOW 방식 존재
- BOW는 텍스트의 순서를 유지하지는 않지만 모델에 보내는 각 텍스트 조각에서 특정 단어의 존재 여부를 감지
- 이 방식을 사용하면 각 텍스트 입력이 1 과 0의 배열로 변환되는 멀티ㅡ핫 인코딩 유형이됨
- BOW의 작동 원리
- 텍스트 코퍼스에서 가장 자주 발생하는 상위 N개의 단어를 포함하는 어휘 크기를 선택
- 이론적으로 어휘 크기는 전체 데이터셋의 고유한 단어 수와 같음
- 그러나 낮은 빈도로 출현하는 단어가 많기 때문에 전체 데이터셋의 고유한 단어 수대로 어휘 크기를 정하면 대부분의 원소가 0으로 구성된 매우 큰 입력 배열이 만들어짐
- 대신 예측 작업에 대한 의미를 전달하는 핵심적이고 반복적인 단어만 포함하도록 어휘 크기를 작게 정하는 것이 좋음
- 모델의 입력은 어휘 크기만큼의 배열이 됨. 따라서 BOW 표현은 어휘에 포함되지 않은 단어를 완전히 무시
- 어휘의 크기를 정하는 방식에는 왕도가 없음으로, 직접 찾는 수고가 필요
- BOW를 딥러닝 모델에서 사용한다고 해서 성능이 좋은 것은 아님
- 사이킷런 또는 XG부스트와 같은 프레임워크를 사용한 선형 회귀 또는 결정 트리 모델에서 BOW인코딩을 사용하는 것이 더 좋을 수도 있음
- 모델은 성능도 중요하지만 결국, 가벼우면서 빠른 프로토타입이 가장 좋은 모델이기 때문
- 텍스트 코퍼스에서 가장 자주 발생하는 상위 N개의 단어를 포함하는 어휘 크기를 선택
텍스트에서 테이블 특징 추출하기
- 원텍스트 데이터를 인코딩하는 것 외에도, 테이블 특징으로 표현 가능한 특징이 텍스트에 있는 경우도 존재
- 임베딩을 만들 때는 일반적으로 단어를 특정 길이로 자르게 되고 질문의 길이와 같은 요소는 해당 데이터 표현에서 손실이 발생
- 마찬가지로 구두점도 보통 이러한 표현에서 제거됨. 멀티모달 입력 디자인 패턴을 사용하면 이렇게 손실된 정보를 모델로 돌릴 수 있음
이미지의 멀티모달 표현
- 흑백 이미지에는 0에서 255까지의 픽셀값이 포함
- 따라서 모델에서 28X28 픽셀의 흑백 이미지는 0에서 255까지의 정숫값이 담긴 28 X 28배열로 표현할 수 있음
- Sequential API를 사용하면 이미지를 784(28 X 28)개 원소를 가진 1차원 배열로 병합하는 Flatten 계층을 사용하여 MNIST 이미지를 낼 수 있음
layers.Flatten(input_shape = (28, 28))- 컬러 이미지의 경우 RGB 색상에 대한 값이 추가됨
layers.Flatten(input_shape = (28, 28, 3))
이미지를 타일 구조로 표현하기
- 현실의 이미지는 복잡하기 때문에, 모델이 의미 있는 정보를 추출하고 패턴을 이해할 수 있도록 이밎를 표현하는 방법이 필요. 이를 위한 모델 아키텍처가 바로 CNN
- CNN 사용시 4 X 4 격자의 각 사각형의 이미지 픽셀값을 맥스풀링하면 각 그리드의 가장 큰 값을 가져와 더 작은 행렬을 생성
- 커널의 크기는 이미지의 각 덩어리 크기를 나타내며, 다음 덩어리를 만들기 전에 필터가 이동하는 공간의 수를 스트라이드라고 부
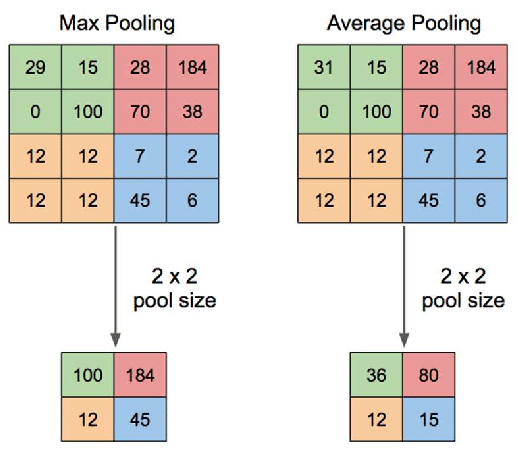
- 예시로 개와 고양이를 분류하는 모델 생성시 코드 예시
Conv2D(filters = 16, kernel_size = 3, activation = 'relu', input_shape = (28, 28, 3))
서로 다른 이미지 표현의 결합
- 케라스의 Concatenate 계층을 사용하여 픽셀값을 슬라이딩 윈도 표현과 결합하는 방법이 존재
# 이미지 입력 계층의 정의(픽셀 및 타일 표현 모두 동일한 모양)
image_input = Input(shape = (28, 28, 3))
# 픽셀 표현 정의
pixel_layer = Flatten()(image_input)
# 타일 표현 정의
tiled_layer = Conv2D(filters = 16, kernel_size = 3, activation = 'relu')(image_input)
tiled_layer = MaxPooling2D()(tiled_layer)
tiled_layer = tf.keras.layers.Flatten()(tiled_layer)
# 단일 계층으로 연결
merged_image_layers = keras.layers.concatenate([pixel_layer, tiled_layer])
- 멀티모달 입력 표현을 허용하는 모델을 정의하기 위해, 결합된 계층으로 연결해야함
merged_dense = Dense(16, activation = 'relu')(merged_image_layers)
merged_output = Dense(1)(merged_dense)
model = Model(inputs = image_input, outputs = merged_output)
- MNIST 데이터셋의 경우 이미지를 픽셀값으로 표현하는 것만으로 도 충분
- 반면 복잡한 의료 이미지 경우 여러 이미지 표현을 결합해야 정확도가 높아짐
- 여러 이미지를 표현을 결합하는 이유는 이미지를 픽셀값으로 표현하면 모델은 대비가 크고 지배적인 개체와 같은 고수준의 초점 포인트를 잘 식별할 수 있음
- 반면 타일 표현은 모델이 보다 대비가 낮은 모서리와 형상을 잘 식별하게 만들기 때문
정리
- 데이터를 표현하기 위한 네가지 디자인 패턴
- 카테고리 입력을 고유한 문자열로 인코딩하는 특징 해시 디자인 패턴
- 임베딩으로 많은 카테고리 또는 텍스트 데이터가 있는 입력과 같이 카디널리티가 큰 데이터를 표현하는 기술
- 특징 교차 디자인 패턴으로 두 특징을 결합하여 특징을 자체적으로 인코딩하고, 이를 통해 쉽게 포착할 수 없는 관계를 추출
- 서로 다른 유형의 입력을 동일한 모델에 결합하는 방법과 하나의 특징이 여러 방식으로 표현될 수 있는 방법에 대한 문제를 해결하는 멀티모달 입력
GitHub - yunho0130/ml-design-patterns: O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드
O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드 저장소 - GitHub - yunho0130/ml-design-patterns: O'Reilly <머신러닝 디자인 패턴 Machine Learning Design Patterns> 소스코드 저장소
github.com
머신러닝 디자인 패턴:효율적인 머신러닝 파이프라인과 MLOps를 구축하는 30가지 디자인 패턴
COUPANG
www.coupang.com